Internet är vid en tipppunkt. Den fortsatta ökningen av adblocking har slutat intäktsmodellen som enbart bygger på annonsdollar för att driva webbplatser och företag.
Särskilt nyhetssajter har börjat experimentera med sätt att diversifiera inkomstkällor, och ett framträdande alternativ som webbplatser som The Wall Street Journal, Financial Times, The New York Times eller The Washington Post alla har implementerat är betalväggssystemet.
Det finns olika typer av betalväggar men de har alla gemensamt att de blockerar åtkomst till innehåll antingen direkt eller efter att ett visst antal artiklar har lästs på webbplatsen.
Besökarna uppmanas sedan att prenumerera på webbplatsen för att fortsätta läsa artiklar om den.
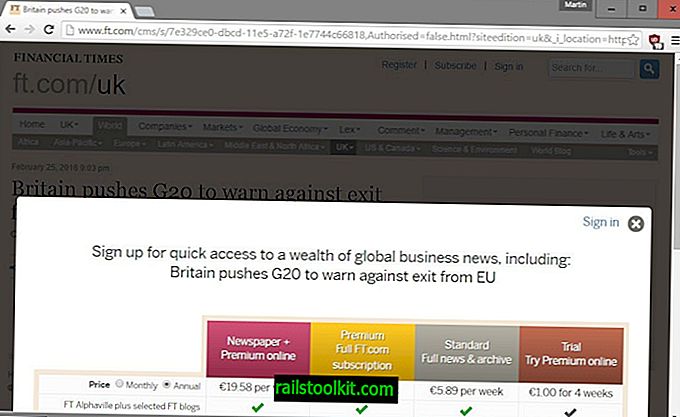
Det kan vara vettigt ur ett affärsmässigt perspektiv och kan vara mer lukrativt än att kämpa ut det med användare som driver adblockers, men det finns en nackdel med det både för den betalväggswebbplatsen och den blockerade användaren.
Webbplatser förlorar en hög andel besökare om de implementerar ett betalväggssystem. Det är oklart hur hög procentandelen egentligen är, och den varierar förmodligen från plats till webbplats, men det är troligt mycket högre än andelen besökare som prenumererar på webbplatsen efter att ha fått valet att prenumerera för att läsa önskad artikel.
Maskerad din webbläsare
Det är ingen hemlighet att nyhetssajter tillåter åtkomst till nyhetsaggregatorer och sökmotorer. Om du till exempel kontrollerar Google Nyheter eller Sök, hittar du artiklar från webbplatser med betalväggar listade där.
Tidigare tillät nyhetssajter åtkomst till besökare som kommer från stora nyhetsaggregat som Reddit, Digg eller Slashdot, men den praxis verkar vara lika bra som död idag.
Ett annat knep, att klistra in artikeltiteln i en sökmotor för att läsa den cachelagrade berättelsen på den verkar inte fungera ordentligt längre, liksom artiklar på webbplatser med betalväggar vanligtvis inte längre är cachelagrade.
Uppdatering : Wall Street Journal meddelade att det kommer att ansluta hålet som beskrivs nedan. Du kan fortfarande läsa artiklar bakom webbplatsens betalvägg med följande metod:
- Tryck på F12 när du är på artikelsidan med den avskurna artikeln och begäran om prenumeration för att läsa den i sin helhet.
- Öppna konsolfliken.
- Klistra in javascript: windows.location = "// m.facebook.com/l.php?u="+encodeURIComponent(window.location.href);
- Hit enter.
Sidan bör laddas om och artikeln bör laddas i sin helhet. Du kan också publicera artikellänken på Facebook, till exempel i ett nytt inlägg som bara du kan se. Om du klickar på den publicerade länken bör du läsa in artikeln på sin webbplats på Wall Street Journal.
Användaragent och referent
Du undrar förmodligen hur webbplatser blockerar eller tillåter åtkomst till webbplatsens innehåll. Metoderna har förbättrats under åren, och det räcker inte längre med att bara ändra webbläsarens referens till //www.google.com/ för att få full tillgång till webbplatsens innehåll.
Istället använder webbplatser olika kontroller som innehåller användaragent, referent och cookies, och ibland till och med mer än så, för att fastställa åtkomstens legitimitet.
Allmän information
Det bästa sättet att maskera webbläsaren är förmodligen att göra det verkar vara Googlebot.
- Hänvisare: //www.google.com/
- Användaragent: Mozilla / 5.0 (kompatibel; Googlebot / 2.1; + // www.google.com/bot.html
Firefox
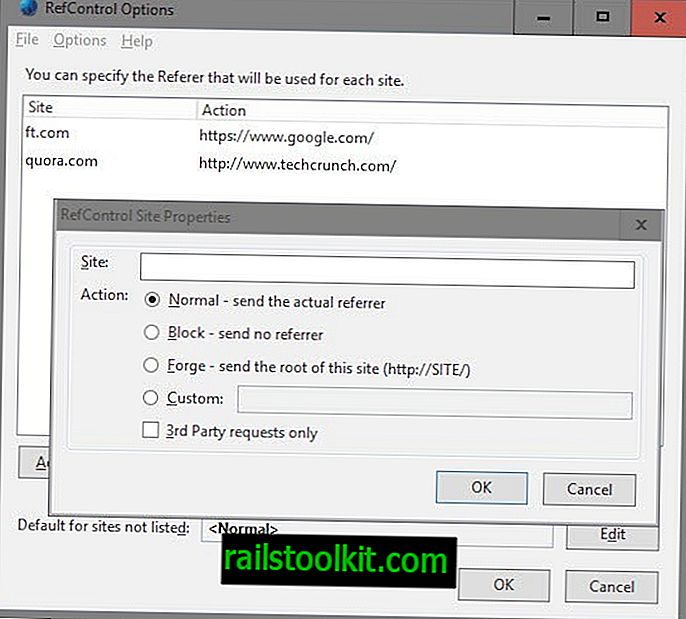
Firefox-användare behöver två webbläsartillägg för det: det första, RefControl, för att ändra referensvärdet när de besöker nyhetssajter, den andra, User Agent Switcher, för att ändra användaragenten i webbläsaren.
- Ladda ner och installera båda tilläggarna i Firefox webbläsare.
- Klicka på Alt-knappen och välj Verktyg> RefControl-alternativ.
- Klicka på "lägg till webbplats", ange ett domännamn under webbplats, välj anpassad åtgärd och ange //www.google.com/ som referens.
- Upprepa detta för alla nyhetssidor som du vill komma åt (vissa kanske inte fungerar även om du gör ändringarna, så tänk på det).
- När du är klar stänger du konfigurationsfönstret.
- Klicka på Alt-knappen igen och välj Verktyg> Standardanvändaragent> Redigera användaragenter från menyn.
- Välj Ny> Användaragent och ersätt strängen i fältet Användaragent med Mozilla / 5.0 (kompatibel; Googlebot / 2.1; + // www.google.com/bot.html). Namnge det Googlebot.
- Lämna menyn.
- Innan du öppnar dessa webbplatser klickar du på Alt och väljer Standardanvändaragent> Googlebot.
Det här är allt. Det är lite olyckligt att det inte finns någon förlängning för Firefox som ändrar användaragenten automatiskt baserat på de webbplatser du besöker.
Google Chrome
Google Chrome-användare kan installera tillägg som User Agent Switcher och Referer Control som är tillgängliga för webbläsaren för att göra detsamma.
Det finns dock en annan möjlighet, och det är att skapa ett anpassat tillägg som automatiserar processen i webbläsaren.
Instruktioner finns på Elaineou. Allt som krävs är i princip att skapa en ny katalog på den lokala datorn, skapa de två filerna background.js och manifest.json inuti den och kopiera och klistra in koden som finns på webbplatsen i filerna.
Du måste aktivera "utvecklarläge" på chrome: // extensions /, och kan sedan välja "load unpacked extension" för att välja mappen du har skapat de två filerna i för att ladda tillägget i Chrome.
Du kan ändra listan med webbplatser som den stöder för att lägga till nya.